Your membership data is more valuable than the AI tools you're buying
There's a pattern emerging across associations that are early in their AI journey, and it's worth naming directly. Organizations are investing significant time and budget evaluating AI tools before they've asked a more fundamental question: is our data in a state where any AI tool can do something genuinely useful with it? The answer, more often than not, is that it isn't — and the highest-leverage thing most associations could do right now has very little to do with which AI vendor they choose.
This isn't a criticism of how associations are approaching AI. The conversation has moved fast, and the pressure to have a visible AI strategy has, in many cases, outpaced the less glamorous work of data infrastructure. But the consequences are real. What's useful to understand upfront is that a lot of what looks like an AI problem — a tool that gives vague answers, that can't find the right information, that produces outputs you can't quite trust — is actually a data problem wearing an AI hat. The tool isn't the issue. The foundation is, and no amount of capability in the AI layer compensates for unreliable data underneath it.
What "AI-ready data" actually means for an association
The term gets used loosely, but it's worth unpacking what it actually means in practice rather than leaving it as a vague aspiration. There are two distinct questions buried inside it, and associations tend to focus on one while overlooking the other.
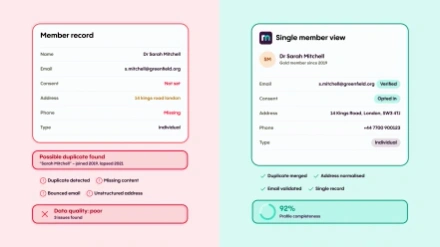
The first is structural: is your data in a format and state that AI can work with meaningfully? This goes beyond the obvious issues of duplicates and incomplete records. It includes things that are easy to overlook because they're so familiar — tables of data, for instance. As a human, you can look at a spreadsheet and immediately understand that a value in column three, row seven is related to the header in that column and the label in that row. AI has historically struggled to preserve that relational meaning, which means data that looks perfectly organised to your team can be genuinely hard for an AI system to interpret correctly. The same applies to charts, diagrams, and anything visual. If a significant amount of your knowledge exists in these formats — reports, presentations, infographics — that's a preparatory consideration before AI can use it reliably.
The second question is about access and appropriateness: should the AI have access to this information in the first place? This is where data readiness intersects with data governance, and it's a question many associations haven't thought through carefully before deploying AI. There's a real difference between giving AI access to your published guidance documents and giving it access to your full membership CRM, including sensitive data like financial records, disciplinary notes, or personal details that exist in the system for operational reasons but were never intended to be surfaced in a member-facing context. Good data governance principles — data minimisation, only processing what you need for a defined purpose — apply to AI just as they do to any other system. The question of what the AI should and shouldn't have access to is a governance decision, not just a technical one, and it needs to be made deliberately rather than inherited from whatever your current system access controls happen to allow.
There's also an accountability dimension that's easy to underestimate. Most associations have well-established processes for decisions that affect members. A fellowship upgrade, for example, goes through a review panel, against defined criteria, with a vote, with reasons documented in the minutes. That audit trail exists because decisions need to be explainable and challengeable. When AI starts contributing to processes like that, the same standard of accountability applies — and most AI deployments, in their current state, don't provide it natively. That's not an argument against using AI; it's an argument for being thoughtful about which processes you apply it to and what guardrails you put in place.
Why do you want to collect data? Are you going to use it, do you need it? Asking the right questions at the right time will set you up for success.
The maturity journey most associations are on
Data maturity in associations tends to follow a recognizable progression, and understanding where your organization sits on it is more useful than benchmarking against an idealized end state that may be years away. Most associations sit somewhere in the middle — past the point of pure manual drudgery, but not yet at the point where data flows cleanly across systems and informs decisions with enough consistency to be genuinely trusted.

Manual data drudgery
Reports built by hand, spreadsheets emailed around, no consistent source of truth. Decisions get made on instinct because the data takes too long to pull together to be useful in the moment.

Multiple data silos
CRM, email platform, events system, and finance each hold their own version of member data. Reconciling them is possible but slow, and the numbers don't always agree.

Partial integration
Some systems talk to each other. Reporting is possible but inconsistent. Staff spend meaningful time reconciling rather than analyzing, and confidence in the outputs is qualified.

Mostly integrated, trusted single view
Data flows reliably. Staff trust what they see. Decisions are made on data rather than instinct. This is where AI starts to deliver meaningful value rather than faster access to unreliable numbers.

Fully integrated, emerging intelligence
AI analyzes data holistically across systems. Patterns surface proactively. Staff focus on high-value decisions; low-value reporting and data-wrangling is automated.
AI delivers meaningfully at stage 4 and above, and struggles at stages 2 and 3 regardless of which tool you choose. The reason for this is worth understanding clearly. Most software behaves deterministically: the same inputs produce the same outputs consistently, which means you can test it, trust it, and build processes around it. AI is probabilistic. It can give you the wrong answer with considerable confidence, and your ability to detect that something has gone wrong is limited — particularly if the people using the output don't have the domain expertise to spot when a plausible-sounding answer is actually incorrect. Deploying AI over fragmented or unreliable data doesn't produce better insights; it produces faster access to unreliable ones, and because the output arrives with the apparent authority of a sophisticated system, it can actually be harder to question than a spreadsheet you know to be approximate.
What good data infrastructure makes possible
The case for investing in data foundations isn't only that it's a prerequisite for AI. It's that it delivers value in its own right, and that value compounds over time regardless of which AI tools you eventually layer on top.
FEDESSA, the Federation of European Self Storage Associations, is the clearest illustration of what this looks like in practice. Before their transformation, they were managing 17 national associations each running their own CRM, website, and email platform, with no integration at the FEDESSA level. Data was siloed, duplicated, and inconsistent; members were receiving multiple, sometimes conflicting communications from their local association and FEDESSA simultaneously. The work of consolidating that into a single unified data environment — cleaning it, restructuring their join process around four key service pillars, and building member profiles gradually through behavioral signals rather than exhaustive surveys — wasn't primarily a technology project. It was a strategic decision about what data FEDESSA actually needed and what they were going to do with it. The results that followed are worth stating clearly: member retention rose from 85% to 94%, email click-through rates increased by 320%, event attendance grew by 29%, and the team reduced the time spent on membership management to less than a third of what it had been. Those outcomes didn't require an AI deployment. They came from a data foundation that was clean, unified, and organised around member behavior rather than organizational convenience.
That foundation is also what makes every subsequent technology decision more effective. Clean, integrated data makes email marketing more precise because segmentation is based on real behavior rather than demographic proxies. It makes renewal management more reliable because at-risk members can be identified before they lapse rather than chased afterward. And when you are ready to deploy AI, it makes the difference between a system that surfaces genuine, actionable insight and one that gives you a more authoritative-looking version of the same uncertainty you started with.
The right approach: opinionated AI over a clean foundation
One of the more common mistakes associations make when deploying AI is treating it as a blank canvas — giving it broad access to systems and data and expecting it to figure out what's useful. The problem with that approach is that the same thing that makes AI powerful (its ability to draw on a wide range of inputs and synthesize across them) also makes it capable of surfacing information it shouldn't, making connections that aren't appropriate, or producing outputs that can't be traced back to a verifiable source.
A more considered approach is what you might call opinionated AI: a system that has been deliberately configured to access defined data sources, operate within defined boundaries, and surface information in ways that your organisation has thought through in advance. This isn't a limitation on what AI can do — it's what makes it trustworthy enough to actually use. The practical implication is that the work of defining those boundaries, deciding what the AI should and shouldn't have access to, and setting up the right controls around it, is at least as important as the choice of AI tool itself. It's also work that benefits directly from having clean, well-structured data to begin with: the clearer your data architecture, the more straightforward it is to define appropriate access and get reliable outputs.
The most useful thing most associations can do before spending time evaluating AI vendors is to audit what their data actually looks like today: where it lives, how consistent it is across systems, whether it's in formats that AI can interpret meaningfully, and whether the governance around who accesses what is clear enough to carry over into an AI context. That audit will tell you more about your real AI readiness than any vendor demonstration, and the gaps it surfaces will be worth addressing whether you adopt AI this year or in three years' time.
ReadyMembership is built around a unified data architecture that gives associations a reliable single view of every member across CRM, events, email, finance, and website. ReadyIntelligence then sits on top of that as the natural next step — an opinionated AI layer with defined data access and governed boundaries, rather than an open-ended tool pointed at whatever happens to be in your systems. If you'd like to understand what that looks like for your organization, we're happy to walk you through it.